


研究紹介 - ロボット
Robot Painter | Brush Trajectories | Composing Picture | Learning from Observation| Dancing Humanoid Robot | Task Recognition
A Robot Painter
 we develop a painting robot with multi-fingered hands and stereo vision. The goal of this study is for the robot to reproduce the whole procedure involved in human painting. A painting action is divided into three phases: obtaining a 3D model, composing a picture model, and painting by a robot. In this system, various feedback techniques including computer vision and force sensors are used. In the first phase, the 3D shape is reconstructed from multi-view range images or multi-view camera images. In the second phase, an interpretation of the 3D model is performed in order to decide how to represent features of the object. Feature lines based on geometry edges are extracted, and brush stroks for filling regions are determined here. A picture model is composed for describing the interpretation. In the last phase, painting by a robot with multi-fingered hands is realized. One of the important challenges here is manipulation of a paintbrush by a multi-fingered hand. Through this study, we believe that we can understand the meaning of painting, which is one of the primary behaviors for humans, using analysis-by-synthesis.
we develop a painting robot with multi-fingered hands and stereo vision. The goal of this study is for the robot to reproduce the whole procedure involved in human painting. A painting action is divided into three phases: obtaining a 3D model, composing a picture model, and painting by a robot. In this system, various feedback techniques including computer vision and force sensors are used. In the first phase, the 3D shape is reconstructed from multi-view range images or multi-view camera images. In the second phase, an interpretation of the 3D model is performed in order to decide how to represent features of the object. Feature lines based on geometry edges are extracted, and brush stroks for filling regions are determined here. A picture model is composed for describing the interpretation. In the last phase, painting by a robot with multi-fingered hands is realized. One of the important challenges here is manipulation of a paintbrush by a multi-fingered hand. Through this study, we believe that we can understand the meaning of painting, which is one of the primary behaviors for humans, using analysis-by-synthesis.
発表論文
- S. Kudoh, K. Ogawara, M. Ruchanurucks, and K. Ikeuchi, “Painting Robot with Multi-Fingered Hands and Stereo Vision,” Proc. of 2006 IEEE Intl. Conf. on Multisensor Fusion and Integration for Intelligent Systems (MFI), pp.127-132, 2006
- M. Fujihata and K. Ikeuchi, “How does a robot paint a picture?” Monthly Art Magazine Bijutsu Techo, 58(880), pp.56-67, May 2006 (in Japanese)
A Robot Painter: Generating Brush Trajectories
 This paper presents visual perception discovered in high-level manipulator planning for a robot to reproduce the procedure involved in human painting. First, we propose a technique of 3D object segmentation that can work well even when the precision of the cameras is inadequate. Second, we apply a simple yet powerful fast color perception model that shows similarity to human perception. The method outperforms many existing interactive color perception algorithms. Third, we generate global orientation map perception using a radial basis function. Finally, we use the derived foreground, color segments, and orientation map to produce a visual feedback drawing. Our main contributions are 3D object segmentation and color perception schemes.
This paper presents visual perception discovered in high-level manipulator planning for a robot to reproduce the procedure involved in human painting. First, we propose a technique of 3D object segmentation that can work well even when the precision of the cameras is inadequate. Second, we apply a simple yet powerful fast color perception model that shows similarity to human perception. The method outperforms many existing interactive color perception algorithms. Third, we generate global orientation map perception using a radial basis function. Finally, we use the derived foreground, color segments, and orientation map to produce a visual feedback drawing. Our main contributions are 3D object segmentation and color perception schemes.
発表論文
- M. Ruchanurucks, S. Kudoh, K. Ogawara, T. Shiratori, K. Ikeuchi, “Humanoid Robot Painter: Visual Perception and High-Level Planning,” In Proc. of IEEE Intl. Conf. on Robotics and Automation (ICRA), pp.3028-3033, 2007.
- M. Ruchanurucks, S. Kudoh, K. Ogawara, T. Shiratori, K. Ikeuchi, “Robot Painter: From Object to Trajectory,” In Proceedings of IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pp.339-345, 2007
A Robot Painter: Composing a Picture
 In the present implementation, the painting robot can paint the silhouette of an object from the direction given to it. We plan to extend the system so that the robot automatically decides the appropriate view direction and the appropriate position of a motif on a canvas when the motif is given. As a preliminary experiment, we analyzed the difference in composing a picture between skilled and unskilled painters. In this experiment, subjects were asked to take photos of motifs using a digital camera assuming the camera frame as a canvas. We prepared four types of motifs. As a result, we observed great differences between skilled and unskilled painters. The typical difference is as follows:
In the present implementation, the painting robot can paint the silhouette of an object from the direction given to it. We plan to extend the system so that the robot automatically decides the appropriate view direction and the appropriate position of a motif on a canvas when the motif is given. As a preliminary experiment, we analyzed the difference in composing a picture between skilled and unskilled painters. In this experiment, subjects were asked to take photos of motifs using a digital camera assuming the camera frame as a canvas. We prepared four types of motifs. As a result, we observed great differences between skilled and unskilled painters. The typical difference is as follows:
- Relationship of size between a motif on a canvas and the corresponding real motif
- Clipping strategy of a large motif
- Contrast between a motif and its background
- Horizontal and vertical axes of a motif related to a canvas
- Arrangement of a motif on a canvas
発表論文
- K. Ikeuchi, K. Ogawara, J. Takamatsu, S. Kudoh, and K. Komachiya, “Simulation of Painting Behavior by Using a Humanoid Robot,” In Proceedings of Crest 21 Art Symposium, pp.25-32, 2007 (in Japanese)
Learning from Observation Paradigm for Humanoid Robot Dancing
 The robotics-oriented approach for generating dance motions is a challenging topic due to dynamic and kinematic differences between humans and robots. In order to overcome these differences, we have been developing a paradigm, Learning From Observation (LFO), in which a robot observes human actions, recognizes what the human is doing, and maps the recognized actions to robot actions for the purpose of mimicking them. We extend this paradigm to enable a robot to perform classic Japanese folk dances. Our system recognizes human actions through abstract task models, and then maps recognized results to robot motions. Through this indirect mapping, we can overcome the physical differences between human and robot. Since the legs and the upper body have different purposes when performing a dance, support by the legs and dance representation by the upper body, our design strategies for the task models reflects these differences. We use a top-down analytic approach for leg task models and a bottom-up generative approach for keypose task models. Human motions are recognized through these task models separately, and robot motions are also generated separately through these models. Then, we concatenate those separately generated motions and adjust them according to the dynamic body balance of a robot. Finally, we succeed in having a humanoid robot dance with an expert dancer at the original music tempo.
The robotics-oriented approach for generating dance motions is a challenging topic due to dynamic and kinematic differences between humans and robots. In order to overcome these differences, we have been developing a paradigm, Learning From Observation (LFO), in which a robot observes human actions, recognizes what the human is doing, and maps the recognized actions to robot actions for the purpose of mimicking them. We extend this paradigm to enable a robot to perform classic Japanese folk dances. Our system recognizes human actions through abstract task models, and then maps recognized results to robot motions. Through this indirect mapping, we can overcome the physical differences between human and robot. Since the legs and the upper body have different purposes when performing a dance, support by the legs and dance representation by the upper body, our design strategies for the task models reflects these differences. We use a top-down analytic approach for leg task models and a bottom-up generative approach for keypose task models. Human motions are recognized through these task models separately, and robot motions are also generated separately through these models. Then, we concatenate those separately generated motions and adjust them according to the dynamic body balance of a robot. Finally, we succeed in having a humanoid robot dance with an expert dancer at the original music tempo.
発表論文
- S. Nakaoka, A. Nakazawa, H. Kanehiro, K. Kaneko, M. Morisawa, H. Hirukawa, and K. Ikeuchi, “Leg Task Models for Reproducing Human Dance Motions on Biped Robots,” Journal of the Robotics Society of Japan, 24(3), pp.112-123, 2006 (in Japanese).
- S. Nakaoka, K. Ikeuchi, et al. “Learning from Observation Paradigm: Leg Task Models for Enabling a Biped Humanoid Robot to Imitate Human Dances,” The International Journal of Robotics Research, 26(8), pp.829-844, 2007.
- T. Shiratori, S. Kudoh, S. Nakaoka, K. Ikeuchi, “Temporal Scaling of Upper Body Motion for Sound Feedback System of a Dancing Humanoid Robot,” In Proc. of IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pp. 3251-3257, 2007.
Temporal Scaling of Upper Body Motion for Sound Feedback System of a Dancing Humanoid Robot
 This project proposes a method to model modification upper body motion of dance performance based on the speed of played music, and the goal of this research is to realize Sound Feedback System of a dancing humanoid robot. When we observed structured dance motion performed at a normal music playback speed and motion performed at a faster music playback speed, we found that the detail of each motion is slightly different while the whole of the dance motion is similar in both cases. This phenomenon is derived from the fact that dancers omit the details and perform the essential part of the dance in order to follow the faster speed of the music. To clarify this phenomenon, we analyzed the motion differences in the frequency domain, and obtained two insights on the omission of motion details:
This project proposes a method to model modification upper body motion of dance performance based on the speed of played music, and the goal of this research is to realize Sound Feedback System of a dancing humanoid robot. When we observed structured dance motion performed at a normal music playback speed and motion performed at a faster music playback speed, we found that the detail of each motion is slightly different while the whole of the dance motion is similar in both cases. This phenomenon is derived from the fact that dancers omit the details and perform the essential part of the dance in order to follow the faster speed of the music. To clarify this phenomenon, we analyzed the motion differences in the frequency domain, and obtained two insights on the omission of motion details:
- High frequency components are gradually attenuated depending on the musical speed.
- Important stop motions are preserved even when high frequency components are attenuated.
Based on these insights, we modeled our motion modification considering musical speed and mechanical constraints that a humanoid robot has. We show the effectiveness of our method via some applications for humanoid robot motion generation.
発表論文
- T. Shiratori, K. Ikeuchi, “Synthesis of Dance Performance Based on Analyses of Human Motion and Music,” IPSJ Transactions on Computer Vision and Image Media, June, 2008 (to be published).
- T. Shiratori, S. Kudoh, S. Nakaoka, K. Ikeuchi, “Temporal Scaling of Upper Body Motion for Sound Feedback System of a Dancing Humanoid Robot,” In Proc. of IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pp. 3251-3257, 2007.
Multilinear Analysis for Task Recognition and Person Identification
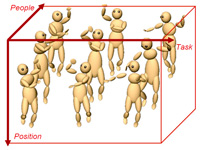 We present a novel approach to recognizing motion styles and identifying persons using the Multi Factor Tensor (MFT) model. We apply a musical information analysis method in segmenting the motion sequence relevant to the keyposes and the musical rhythm. We define a task model considering the repeated motion segments, where the motion is decomposed into a person-invariant factor task and a person-dependent factor style. Given the motion data set, we formulate the MFT model, factorize it efficiently in different modes, and use it in recognizing the tasks and the identities of the persons performing the tasks. We capture the motion data of different people for a few cycles, segment it using the musical analysis approach, normalize the segments using a vectorization method, and realize our MFT model. In our experiments, Japanese traditional dance by several people is chosen as the motion sequence. Provided with an unknown motion segment which is to be probed and which was performed at a different time in the time space, we first normalize the motion segment and flatten our MFT model appropriately, then recognize the task and the identity of the person. We follow two approaches in conducting our experiments. In one experiment, we recognize the tasks and the styles by maximizing a function in the tensor subdomain, and in the next experiment, we use a function value in the tensorial subdomain with a threshold for recognition. Interestingly, unlike in the first experiment, we are capable of recognizing tasks and human identities that were not known beforehand. Various experiments that we conduct to evaluate the potential of the recognition ability of our proposed approaches and the results demonstrate the high accuracy of our model.
We present a novel approach to recognizing motion styles and identifying persons using the Multi Factor Tensor (MFT) model. We apply a musical information analysis method in segmenting the motion sequence relevant to the keyposes and the musical rhythm. We define a task model considering the repeated motion segments, where the motion is decomposed into a person-invariant factor task and a person-dependent factor style. Given the motion data set, we formulate the MFT model, factorize it efficiently in different modes, and use it in recognizing the tasks and the identities of the persons performing the tasks. We capture the motion data of different people for a few cycles, segment it using the musical analysis approach, normalize the segments using a vectorization method, and realize our MFT model. In our experiments, Japanese traditional dance by several people is chosen as the motion sequence. Provided with an unknown motion segment which is to be probed and which was performed at a different time in the time space, we first normalize the motion segment and flatten our MFT model appropriately, then recognize the task and the identity of the person. We follow two approaches in conducting our experiments. In one experiment, we recognize the tasks and the styles by maximizing a function in the tensor subdomain, and in the next experiment, we use a function value in the tensorial subdomain with a threshold for recognition. Interestingly, unlike in the first experiment, we are capable of recognizing tasks and human identities that were not known beforehand. Various experiments that we conduct to evaluate the potential of the recognition ability of our proposed approaches and the results demonstrate the high accuracy of our model.
発表論文
- M. Perera, T. Shiratori, S. Kudoh, A. Nakazawa, K. Ikeuchi, “Task Recognition and Person Identification in Cyclic Dance Sequences with Multi Factor Tensor Analysis,” IEICE Transactions on Information and Systems, Vol.E 91-D, May 2008.
- M. Perera, T. Shiratori, S. Kudoh, A. Nakazawa, K. Ikeuchi, “Multilinear Analysis for Task Recognition and Person Identification,” Proc. of 2007 IEEE International Conference on Intelligent Robots and Systems, 2007.